个人博客重启篇-联邦学习基础知识
个人博客重启篇
由于之前的一段时间忙于考研和毕业设计导致个人博客网站的更新停滞,从今天起就要开始在博客上面分享我的学习的内容和总结,由于网站没有购买相应的服务器和域名,只上传到了githubpage上面,所以有时候会出现访问加载缓慢和访问异常,目前正在想办法解决中。现有思路是主线路托管于 Netlify 与 Vercel 并配置域名以支持大陆境内访问,可以尝试一下是否行得通。
pytho中的Numpy库
在Python的第三方包中,numpy是个功能非常强大的扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
### np.random.seed()函数的应用
np.random.seed()函数可以保证生成的随机数具有可预测性。
这里的可预测性是指相同的种子(seed值)所产生的随机数是相同的。如果不设置seed值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。
语法:
numpy.random.seed(seed=None) 输入: —-seed参数默认为空,可选择整数或者数组,可选。
np.random.rand()
该函数括号内的参数指定的是返回结果的形状,如果不指定,那么生成的是一个浮点型的数;如果指定一个数,那么生成的是一个numpy.ndarray类型的数组;如果指定两个数字,那么生成的是一个二维的numpy.ndarray类型的数组。如果是两个以上的数组,那么返回的维度就和指定的参数的数量个数一样。其返回结果中的每一个元素是服从0~1均匀分布的随机样本值,也就是返回的结果中的每一个元素值在0-1之间。
1 | import numpy as np |
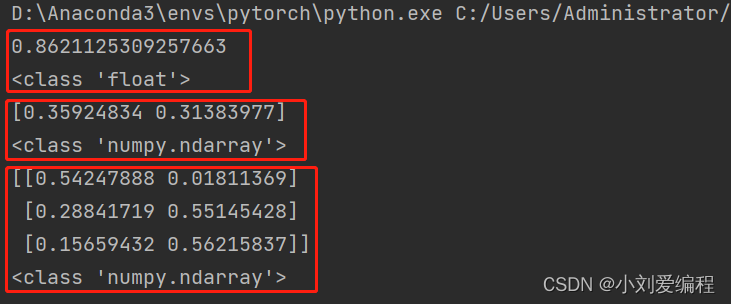
np.random.randn()
该函数和rand()函数比较类似,只不过运用该函数之后返回的结果是服从均值为0,方差为1的标准正态分布,而不是局限在0-1之间,也可以为负值,因为标准正态分布的曲线是关于x轴对阵的。其括号内的参数如果不指定,那么生成的是一个浮点型的数;如果指定一个数,那么生成的是一个numpy.ndarray类型的数组;如果指定两个数字,那么生成的是一个二维的numpy.ndarray类型的数组。和rand()相比,除了元素值不一样,其他的性质是一样的
鲁棒性的含义
1、含义 鲁棒是Robust的音译,也就是健壮和强壮的意思。它也是在异常和危险情况下系统生存的能力。比如说,计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。所谓“鲁棒性”,也是指控制系统在一定(结构,大小)的参数摄动下,维持其它某些性能的特性。根据对性能的不同定义,可分为稳定鲁棒性和性能鲁棒性。以闭环系统的鲁棒性作为目标设计得到的固定控制器称为鲁棒控制器。
鲁棒性包括稳定鲁棒性和品质鲁棒性。一个控制系统是否具有鲁棒性,是它能否真正实际应用的关键。因此,现代控制系统的设计已将鲁棒性作为一种最重要的设计指标。
AI模型的鲁棒可以理解为模型对数据变化的容忍度。假设数据出现较小偏差,只对模型输出产生较小的影响,则称模型是鲁棒的。 Huber从稳健统计的角度给出了鲁棒性的3个要求:
模型具有较高的精度或有效性。
对于模型假设出现的较小偏差(noise),只能对算法性能产生较小的影响。
对于模型假设出现的较大偏差(outlier),不能对算法性能产生“灾难性”的影响。
2、鲁棒性和稳定性的区别 鲁棒性即稳健性,外延和内涵不一样;稳定性只做本身特性的描述。鲁棒性指一个具体的控制器,如果对一个模型族中的每个对象都能保证反馈系统内稳定,那么就称其为鲁棒稳定的。稳定性指的是系统在某个稳定状态下受到较小的扰动后仍能回到原状态或另一个稳定状态。
3、鲁棒性和泛化性的区别 鲁棒性是控制论中的词语,主要指在某些参数略微改变或控制量稍微偏离最优值时系统仍然保持稳定性和有效性。泛化能力指根据有限样本得到的网络模型对其他变量域也有良好的预测能力。根据泛化能力好的网络设计的神经网络控制器的鲁棒性也会有所改善。鲁棒性指自己主动去改变网络中的相关参数,细微地修改(破坏)模型,也能得到理想的效果;而泛化能力是指,在不主动修改(破坏)模型的前提下,被动接受不同的外界输入,都能得到相应的理想的效果。
4、如何提升模型鲁棒性 研究方向 为了提升模型的鲁棒性, 现在主流的研究大致分为三个方向: 1、修改模型输入数据, 包括在训练阶段修改训练数据以及在测试阶段修改输入的样本数据。 2、修改网络结构, 比如添加更多的网络层数,改变损失函数或激活函数等方法。 3、添加外部模块作为原有网络模型的附加插件, 提升网络模型的鲁棒性。
一、耦合 1、耦合是指两个或两个以上的体系或两种运动形式间通过相互作用而彼此影响以至联合起来的现象。
2、在软件工程中,对象之间的耦合度就是对象之间的依赖性。对象之间的耦合越高,维护成本越高,因此对象的设计应使类和构件之间的耦合最小。
3、分类:有软硬件之间的耦合,还有软件各模块之间的耦合。耦合性是程序结构中各个模块之间相互关联的度量。它取决于各个模块之间的接口的复杂程度、调用模块的方式以及哪些信息通过接口。
二、解耦 1、解耦,字面意思就是解除耦合关系。
2、在软件工程中,降低耦合度即可以理解为解耦,模块间有依赖关系必然存在耦合,理论上的绝对零耦合是做不到的,但可以通过一些现有的方法将耦合度降至最低。
3、设计的核心思想:尽可能减少代码耦合,如果发现代码耦合,就要采取解耦技术。让数据模型,业务逻辑和视图显示三层之间彼此降低耦合,把关联依赖降到最低,而不至于牵一发而动全身。原则就是A功能的代码不要写在B的功能代码中,如果两者之间需要交互,可以通过接口,通过消息,甚至可以引入框架,但总之就是不要直接交叉写。
4、观察者模式:观察者模式存在的意义就是「解耦」,它使观察者和被观察者的逻辑不再搅在一起,而是彼此独立、互不依赖。比如网易新闻的夜间模式,当用户切换成夜间模式之后,被观察者会通知所有的观察者「设置改变了,大家快蒙上遮罩吧」。QQ消息推送来了之后,既要在通知栏上弹个推送,又要在桌面上标个小红点,也是观察者与被观察者的巧妙配合。
三、如何解耦 1、反射解耦:我们可以利用Java的反射技术,通过类定名,来进行反射创建对象,这个时候我们可以成功的避免编译时异常,并且保证了项目在这个时候还能正常运行。
2、工厂模式解耦:在实际开发中我们可以把三层的对象都使用配置文件配置起来,当启动服务器应用加载的时候,让一个类中的方法通过读取配置文件,把这些对象创建出来并存起来。在接下来的使用的时候,直接拿过来用就好了。那么,这个读取配置文件,创建和获取三层对象的类就是工厂。
Non-IID
在联邦学习Federated Learning中,出现的很高频的一个词就是Non-IID,翻译过来就是非独立同分布,这是一个来自于概率论与数理统计中的概念,下面我来简单介绍一下在Federated Learning中IID和Non-IID的概念。
何为IID(独立同分布)
IID是数据独立同分布(Independent Identically Distribution,IID),它是指一组随机变量中每个变量的概率分布是相同的,且这些随机变量互相独立。下面介绍IID中的“独立”和“同分布”这两个概念:
- 独立性:采样样本之间相互独立,互不影响。用数学公式表达:如果随机变量X和Y独立,那么它们的联合概率分布可以分解为P ( X , Y ) = P ( X ) ∗ P ( Y ) P(X,Y)=P(X)*P(Y)P(X,Y)=P(X)∗P(Y)。
例如抛骰子,我抛两次,上一次抛的结果并不会影响到下一次的结果,这两次采样样本之间就是独立的。但是假如说我想要两次结果之和大于8,那么这时候两次抛就不独立了。
- 同分布:所有采样样本均来自同一个分布
还是抛骰子,每次采样的样本都来自于同一个分布,即每次抛都会随机得到一个1~6的点数,每个点数的概率为1/6。
现在很多机器学习中的方法都是基于数据IID的假设,这是一种理想情况,因为在现实中往往是Non-IID的。
何为Non-IID(非独立同分布)
首先要明确一个概念,Non-IID是非·独立同分布,解释来说就是,Non-IID可以分为三类:非独立但同分布、独立但非同分布、非独立也非同分布。上述的任何一种我们都可以称之为Non-IID。
非独立:两个或多个随机变量之间存在一定程度的关联,一个随机变量的值可能受到其他随机变量的影响。
比如要求两次抛骰子结果之和大于8、不放回地摸黑球白球。
非同分布:样本并不是从同一个分布中采样得到的。
来自不同的分布,一个样本我从抛骰子中获取16,另一个样本我从扑克中抽AK。
联邦学习中的Non-IID
在机器学习中,有特征Features和标签Labels这两个概念。由这两个概念,我们就能引申出FL中的5种Non-IID情况:
- Feature Distribution Skew 特征分布偏差;
- Label Distribution Skew 标签分布偏差;
- Same Label,different features 相同标签,不同特征;
- Same Feature,different labels 相同特征,不同标签;
- Quantity skew or unbalancedness 数量倾斜或不平衡;
在FL中,数据是存储在不同的设备上的,而各个设备可能采集不同类型的数据、数据量不同、数据质量不同、数据采集的时间和地点也不同,因此不同设备之间的数据可能是非独立或非同分布的。 由于数据Non-IID,在联邦学习模型训练时,可能会受到的影响:
- 模型收敛困难:当各设备的本地数据分布不同或数据质量差异较大时,全局模型收敛会受到影响,因为不同设备间的本地模型更新合并起来不太容易。
- 性能不稳定:由于数据Non-IID,全局模型可能在某些设备上表现良好,而在另一些设备上表现很差。
在FL中,Non-IID通常伴随着异构性Heterogeneity一起出现。我们通常认为,Non-IID是异构性Heterogeneity的一种表现,而异构性Heterogeneity在概念上更为广泛。 在FL中,异构性Heterogeneity一般分为三种:
- 设备异构性:不同的设备有不同的硬件性能,如cpu、gpu、内存等,导致计算能力不同。此外网速和稳定性方面也各有不同;
- 统计异构性:设备的数据可能来自于不同的数据源、采集方式、时间段、环境等,导致数据的统计性质存在差异;
- 数据异构性:设备的数据可能是不同的类型(文本/图像/音频等);

